
FORSKA-Sweden, a multi-disciplinary team of researchers from Onsala Space Observatory and the Fraunhofer-Chalmers Centre (FCC), scored second place in the Square Kilometer Array Data Science Challenge 2 (SDC2). Forty teams comprising 280 participants in 22 countries took part in SDC2, which kicked off in February this year and lasted for six months. The teams were supported by eight supercomputing centres around the world, providing vital storage and processing resources.
“I am very impressed by the effort carried out by the FORSKA-Sweden team given that this was the first real attempt at FCC to tackle computational challenges on big astronomy data. As usual it turns out the combination of deep knowledge in applied mathematics at FCC combined with domain expertise, here represented by the researchers at the Onsala Space Observatory, is key to successful solutions of hard problems.”, says Mats Jirstrand, Head of the department of Systems and Data Analysis at FCC.
The FORSKA-Sweden solution comprised a machine learning pipeline including components such as convolutional neural networks combined with existing open-source code for source finding for detecting and characterizing galaxies and in-house algorithms for computing characteristic source properties. The deployment, training, and testing of the pipeline on the challenge data set (1 TB HI data cube) were carried out on the Piz Daint supercomputer hosted by CSCS – Swiss National Supercomputing Centre. The challenge data set consisted of a 1 TB data cube of simulated radio telescope data in which to find and classify sources. In addition, a much smaller data set of similar kind but with full information about sources and their properties could be used as a ‘truth catalog’ for training and validating the proposed solutions before applying and scoring the solutions on the 1 TB data cube.
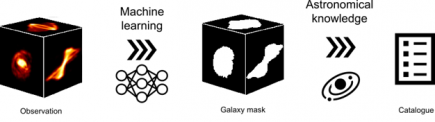
The Square Kilometer Array Observatory, SKAO, Data Challenges are designed to prepare future users to efficiently handle SKAO data, so that it can be exploited to its full potential as soon as the telescopes enter early operations, and to drive the development of data analysis techniques.
Announcement at skatelescope.org.
Acknowledgement This collaborative research project was funded by the Onsala Space Observatory and in part also by the Fraunhofer Center for Machine Learning, which are gratefully acknowledged.